My Kanban Journey
Disclaimer: This post was written as an employee of Puppet, Inc., but does not constitute opinions of the company.
Last year I was part of the effort to design, develop and deliver the first version of the Puppet Development Kit. We started our effort small with a Trello board of ideas and things that we wanted to achieve. Once development started, we switched over to a JIRA project using the companies standard config, which turned out to be quite limiting after a while. At one point I took a day or two to completely rebuild our kanban boards to streamline the info exposed and reduce the friction when using them. Only after leaving the team, I realised the value of having a low-friction JIRA configuration:
Thanks due to some prodding by @sigje and some internal folks, I’ve finally come around to writing this up.
Let’s start with a short intro to Dual Track Agile, the agile flavour du jour back then. Then I’ll give an overview of how the boards look like today, and walk through the life of a feature/ticket in the second half.
Dual Track Agile
As mentioned in the intro, there was a big blob of things we wanted to achieve with the PDK, but were unable to address at “this” point in time. With the default setup of JIRA (back then), this was loading up the board with tickets that were not relevant to the day-to-day activities. At the same time, this glut of tickets obscured the view of what should be coming next, as individual stories were too detailed, and not structured to support day-to-day development activities.
At the time I stumbled over some folks talking about dual track agile: splitting design and long-term planning out from the day-to-day development board. This allowed me to represent the high-level planning and progress on one board, and to remove those long-term activities from the day-to-day detail view necessary for development on the primary board.
Read also Emanuele’s second post about their dual track experience.
The “State of Play” Board
The main board for day-to-day development usage should look familiar to everyone who had to work with JIRA.
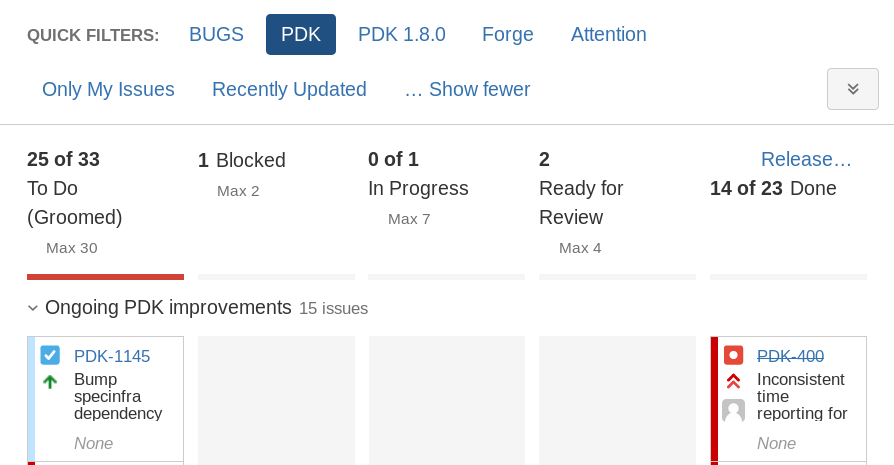
We were already used to using Epics to group tickets, so I followed JIRA’s default of Epics as swimlanes. At that time we were using our internal JIRA defaults for board columns that was built for the much larger team and project of Puppet Enterprise, which had something like 8 different ticket states to handle Dev/QA/CI handoffs. In the PDK team we were mostly using Travis CI to directly test pull requests and code would go straight to master after a review from a second engineer. This resulted in the six columns that we have now: Backlog, Groomed, Blocked, In Progress, Review, and Done.
Astute readers might notice that the backlog column doesn’t show up on the screenshot. This is a recent change in JIRA that I really love. The first column of the board is not shown on the main board anymore, but moved to a separate - aptly named “backlog” - view:
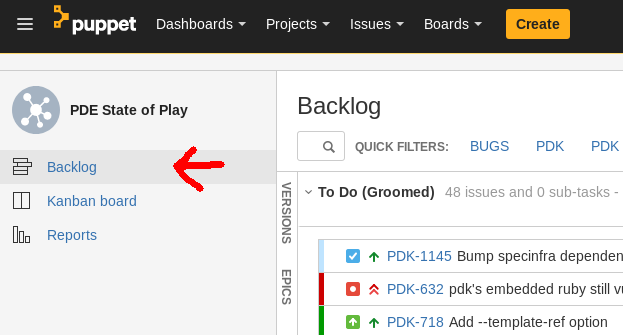
Here the unfinished stories and not-yet-started tickets live a shadow-life away from the day-to-day activities. One click away, in a format optimized for slicing, dicing and reshuffling them. If my memory is correct the board needs to set up as a “Kanban board” when creating it to enable this functionality.
“Blocked” is a special case, mostly reserved for tickets we started, but now Need Information (or work) from some external party. This might be community feedback, or some service from another team. We’ve kept those tickets on the main board to not lose sight of them, and revisit them every so often to see if we need to follow-up.
The quick filters in the top line get adjusted depending on the overarching theme the team is currently working on. For example you can see the “PDK 1.8.0” filter, which shows all tickets deemed mandatory for the next feature release of the PDK. While this is of lesser importance for the big items, every release has a number of smaller fixes going in which do not necessitate a separate epic.
Since we’re not using JIRA’s release feature, Done tickets get dropped from the board after 14 days. This preserves context of what we accomplished without overloading the board. This can be accomplished by adding a term to the board’s Filter Query: AND (resolution = unresolved OR resolved >= -14d).
The “Epic Overview” Board
To keep a longer term overview of what’s going on, the “Epic Overview” board only shows epics. In our case, epics are bigger chunks of work that can be released as features.
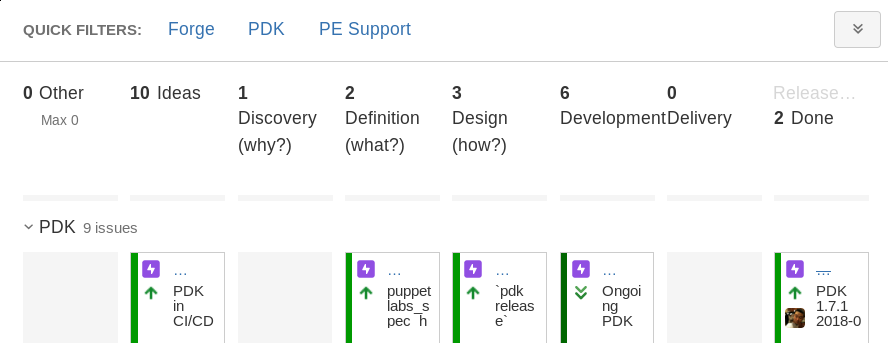
The columns here are based on work by others in the company around structuring the pre-programming-process. From idea to development and delivery, epics can accurately reflect their current state, and get refined as they migrate from left to right. This board also serves as an easy interface for folks outside the team to get a high-level of understanding where the team is heading.
Re-ordering epics here will influence the order in which they appear on the State of Play board. This makes it very easy to translate the high-level priorities here into a daily usable details board that also reflects the priorities without additional maintenance overhead.
Only Epics in the Development or Delivering stage are shown on the State of Play board. This keeps the daily view uncluttered from work that is not yet ready to start.
The “Bow Wave” Filter
Since the PDK is run as an open source project, there are lots of folks outside the team who can provide feedback through tickets. When starting out we deliberately decided a multi-format approach to get folks to report issues. We accept reports from the public in github and in JIRA (needs a local account). The requirement for a separate account is a barrier - especially for new folks. Over the last year we got a lot more feedback and contributions through github than through JIRA.
While github has a really nice self-service email notification system, allowing us to keep track of new reports, JIRA (in our setup) is … less forthcoming. To workaround this, we have a JIRA issue filter that surfaces new and untriaged issues in the PDK project and checking the bow wave for new tickets is part of the daily triage.
There would also be the option to use JIRA’s “service desks”, to make the submission of reports by outsiders a nicer experience. It turned out that there were significant limitations in how JIRA projects need to be configured to be able to handle that, which were incompatible with the rest of our requirements.
The Life of a Feature
Finally, let’s track a new feature from initial idea to release through the boards to connect the individual pieces and give you a deeper understanding of how these boards are useful.
Note that this description is the process as of late last year. Recently the PDK team has introduced the pdk-planning repo to make some of the bits described here more accessible to the community. Please follow the README there if you want to know how PDK planning works today.
Also note that this description of the process is only a set of guidelines, even within the team. I would encourage everyone following these words to apply a hefty dose of shuhari.
While the individual stages are presented separetely here, in the real world they overlap, blend and complement each other.
Idea
Every feature starts as an Idea. A conversation on Slack, an identified gap in the feature set, a major restructuring of the code base. Smaller items should go directly into the Ongoing PDK Improvements epic, and can be directly scheduled. Larger items get started as epic of their own and pass through the Epic Overview board first.
Discovery - Why?
The first step after noting a necessity is Discovery, or why is there a problem? Often this goes hand in hand with how the idea was initially formed, but sometimes it could require lots of work by our Product Manager and/or UX researcher to figure out if this is really something that we need to address, and its overall importance.
Definition - What?
Once “we” have identified and “agreed” on the problem, the next step is Definition, or what is the solution? No problem has a single solution. Figuring out what the solution should be, again is mostly driven by product management and UX; engineers provide input around implementation feasibility of the various possibilities. A very effective tool to judge potential solutions was writing the documentation beforehand, and creating fictional terminal sessions of how the PDK would be used in the new scenario. This makes it easy for users to visualize what would happen, and give early feedback.
Design - How?
Once there is some clarity around what should be built, we can start looking at Designing the implementation, or how to build it. Identifying the integration points within the code base, APIs that need adjustment, fleshing out the steps required to make something happen, breaking down the epic into workable chunks.
Development
Depending on other work going on, eventually the coding can start. The Epic moves into the Developing stage, and the prepared tickets start appearing in the backlog of the State of Play board. This is also the point where the high-level planning and the Bow Wave external inputs merge: tickets create as Open get Accepted by the team as something that needs to be done.
Grooming
In grooming sessions (often focused on a specific topic), we figure out what needs to be figured out to be able to start working on a specific thing. Some of this comes from the designing stage, and some of the work is only discovered as development progresses. Acceptance criteria can help focus on a individual definition of done for each task. Depending on the specifics, this can include new API interactions, new CLI interactions, unit tests, end-to-end tests, and documentation bits.
Regular grooming would happen every other week, and focus on the immediate next steps necessary, as well as keeping the board clean and usable. For bigger chunks of work, especially kicking off a new feature, we would allocate separate sessions to break down the tickets. This also meant that the team seldom overcommitted or stalled out, because we were in control of the flow of tickets into the day-to-day process, and would only pull in a new set of work when we were ready.
Once there is a shared understanding, the ticket becomes Ready for Engineering, and shows up on the Groomed column on the main board.
In Progress
As folks are looking for the next thing to work on, they can pick up the next task from the Groomed column, assign themselves and get started.
Ready to Review
Once the work is supposedly done (oh, how often am I wrong :-D ) we create a PR with the changes, and have another team member review the changes. In many cases the changes are small enough that no or only minor changes are required where the ticket can stay in this state until those are resolved. (Code Review etiquette is something else I have strong opinions about, definitely too many for this post.)
To avoid annoying back-and-forths on more complex changes we would pro-actively put up work-in-progress/do-not-merge PRs for preview without moving to this state, and discuss with the wider team long before a change would be considered complete.
The Ready for Review column is the area I was most not-really-satisfied, but never annoyed (or inspired) enough to make a change, is this column. Part of this is grounded in the disassociation between github PRs and JIRA tickets, and the overhead required to keep the two states synchronized. Part of this is the “Ready to” phrasing that would indicate a queue waiting to be processed, instead of a bit of work currently in flight.
Done
It’s merged. Ship it. Next!
Delivery
This is a limbo state between “We’ve done the work”, and “Customers can actually use this”. It’s not done-done, until the release is on the download server. Epics get parked here to signal the final stages tying up loose ends, of just waiting for someone to press the right button in Jenkins.
Metrics
Being a small, tight-knit team, numeric metrics were not something we looked into much. The two high-level bits I personally tracked - more as an afterthought - were a created-vs-resolved chart for the project, and the cadence of releases. The chart combines a vague sense of velocity, an overview of significant events in the life of the project, and exposes long-term trends. The release cadence is a good indicator for getting things done overall. It also tracked well the maturing of the PDK overall and individual feature releases.
Final words
There is only so much I can piece together in a lazy Sunday afternoon of a year’s worth of working together with the best team I was ever blessed with working with. By necessity therefore, this blog post only touches the high-points and major avenues of information flow. If you have questions about how I implemented a specific thing, feel free to reach out to me @dev_el_ops on twitter.
None of the work presented here would have been possible without the PDK team, and this post would be a shadow of itself without the feedback from Jennifer Davis, Craig Gomes, Brice Figureau, and Michael Smith. If any mistakes remain, they are mine.